机器人界的「Imagenet 时刻」,李飞飞团队官宣全球顶级具身智能挑战赛
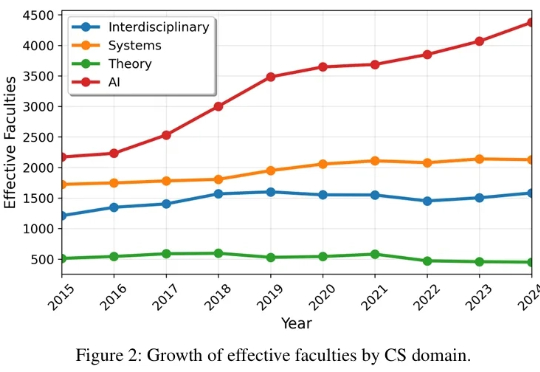
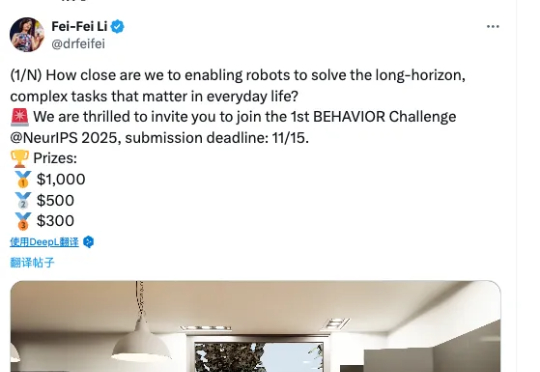
机器人界的「Imagenet 时刻」,李飞飞团队官宣全球顶级具身智能挑战赛答案或许渐渐清晰。李飞飞团队与斯坦福 AI 实验室正式官宣:首届 BEHAVIOR 挑战赛将登陆 NeurIPS 2025。这是一个为具身智能量身定制的 “超级 benchmark”,涵盖真实家庭场景下最关键的 1000 个日常任务(烹饪、清洁、整理……),并首次以 50 个完整长时段任务作为核心赛题,考验机器人能否在逼真的虚拟环境中完成真正贴近人类生活的操作。
来自主题: AI资讯
8925 点击 2025-09-25 10:58